NVIDIA's MLPerf v6.0 Moment Is Really About Token Economics
NVIDIA's MLPerf Inference v6.0 results are more than a speed headline. The bigger story is full-stack optimization for lower token cost, better latency, and practical inference economics.

Benchmark headlines usually reduce everything to one question: who is faster. But NVIDIA's MLPerf Inference v6.0 messaging points to a different question that matters more in 2026: what does it cost to serve useful tokens at production latency?
That framing is important because modern AI demand is increasingly driven by reasoning, multimodal flows, and long-context agent workloads. In those workloads, raw peak speed alone does not decide product viability. Cost and interactivity do.
What Changed in MLPerf Inference v6.0
MLCommons announced MLPerf Inference v6.0 on April 1, 2026 and called it the largest suite refresh so far. The datacenter benchmark mix now better reflects current serving realities.
According to MLCommons, five of the eleven datacenter tests were new or updated, including:
- GPT-OSS 120B benchmarks for math, science, and coding
- expanded DeepSeek-R1 reasoning with interactive scenarios
- DLRMv3 recommendation workloads
- the first text-to-video generation benchmark
- new vision-language catalog-to-metadata tasks
NVIDIA's Core Signal: Lower Token Cost on the Same Footprint
In its April 2026 technical post, NVIDIA highlights that GB300 NVL72 delivered up to 2.7x higher token throughput on DeepSeek-R1 server submissions over a six-month span (v5.1 to v6.0). The company maps this to more than 60% lower token cost on the same infrastructure and power footprint.
Even if your stack is different, the strategic takeaway is clear: the market is shifting from isolated hardware speed claims to system-level inference economics.
Why This Is a Full-Stack Story
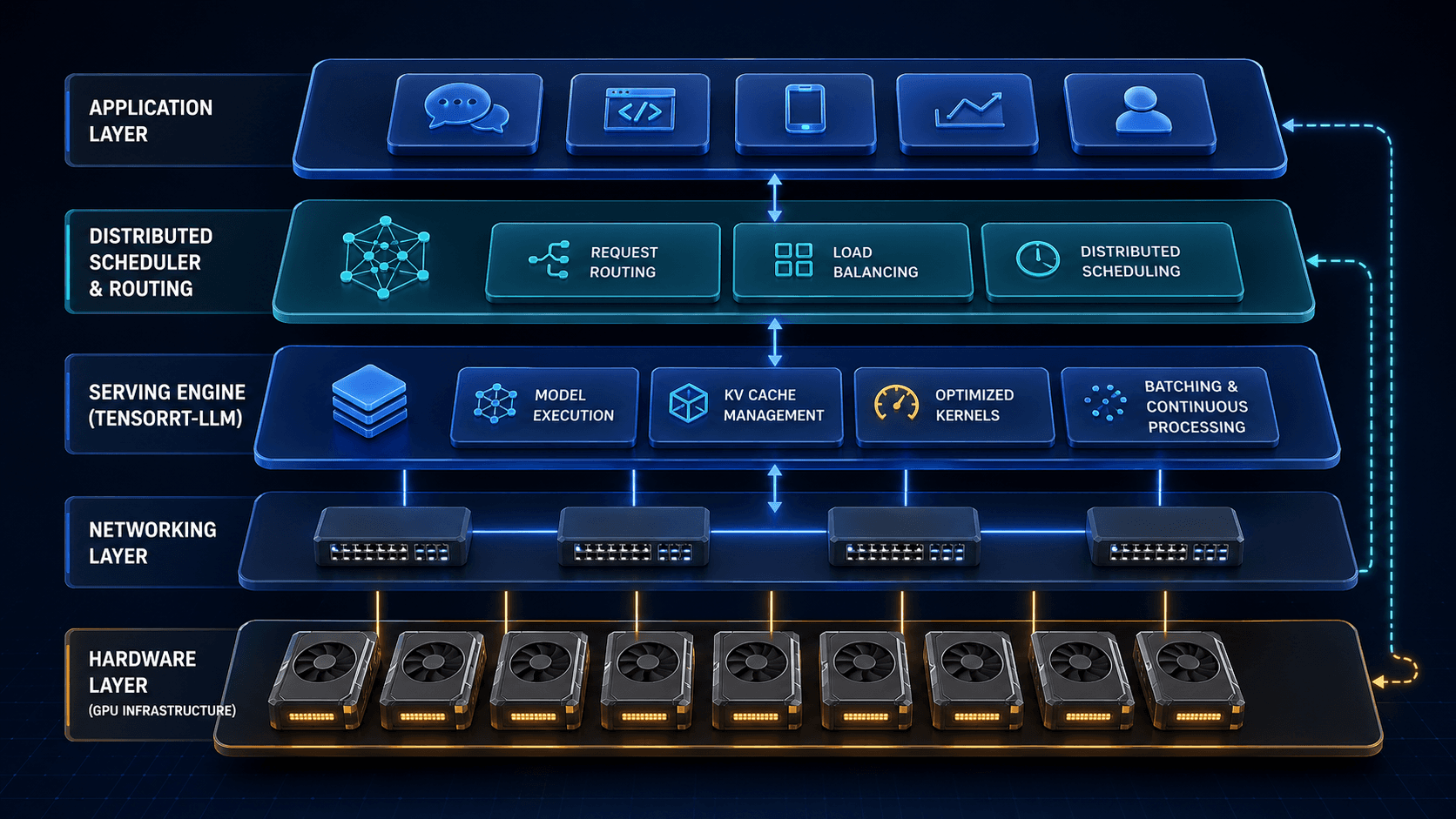
NVIDIA explicitly attributes gains to stack-level work, not just silicon. The list includes kernel fusion, optimized attention data parallelism, TensorRT-LLM, Dynamo, disaggregated serving, Wide Expert Parallel, multi-token prediction, and KV-aware routing.
For real production workloads, bottlenecks move between prefill, decode, memory, expert routing, and network behavior. That is why infrastructure decisions now depend on stack fit as much as chip specs.
Practical Reading Guide for Buyers and Builders
Use MLPerf results as strong directional input, then validate against your own serving reality:
- match benchmark scenarios to your real traffic mix
- verify software and tuning assumptions behind published numbers
- test long-context latency and cost, not only short-context throughput
- include orchestration and utilization in total cost calculations
Bottom line: benchmark wins are useful filters, not automatic purchasing conclusions.
Sources
- MLCommons: MLPerf Inference v6.0 results (April 1, 2026)
- MLCommons: MLPerf results visualizer
- NVIDIA: Lowest token cost via extreme co-design
- NVIDIA: TensorRT-LLM overview