Qwen3.6-27B Is the Open Coding Model to Test First for Local Workflows
Qwen3.6-27B brings a practical open-weight coding model with long context and clear serving paths. Here is what changed and how developers can evaluate it in real local workflows.
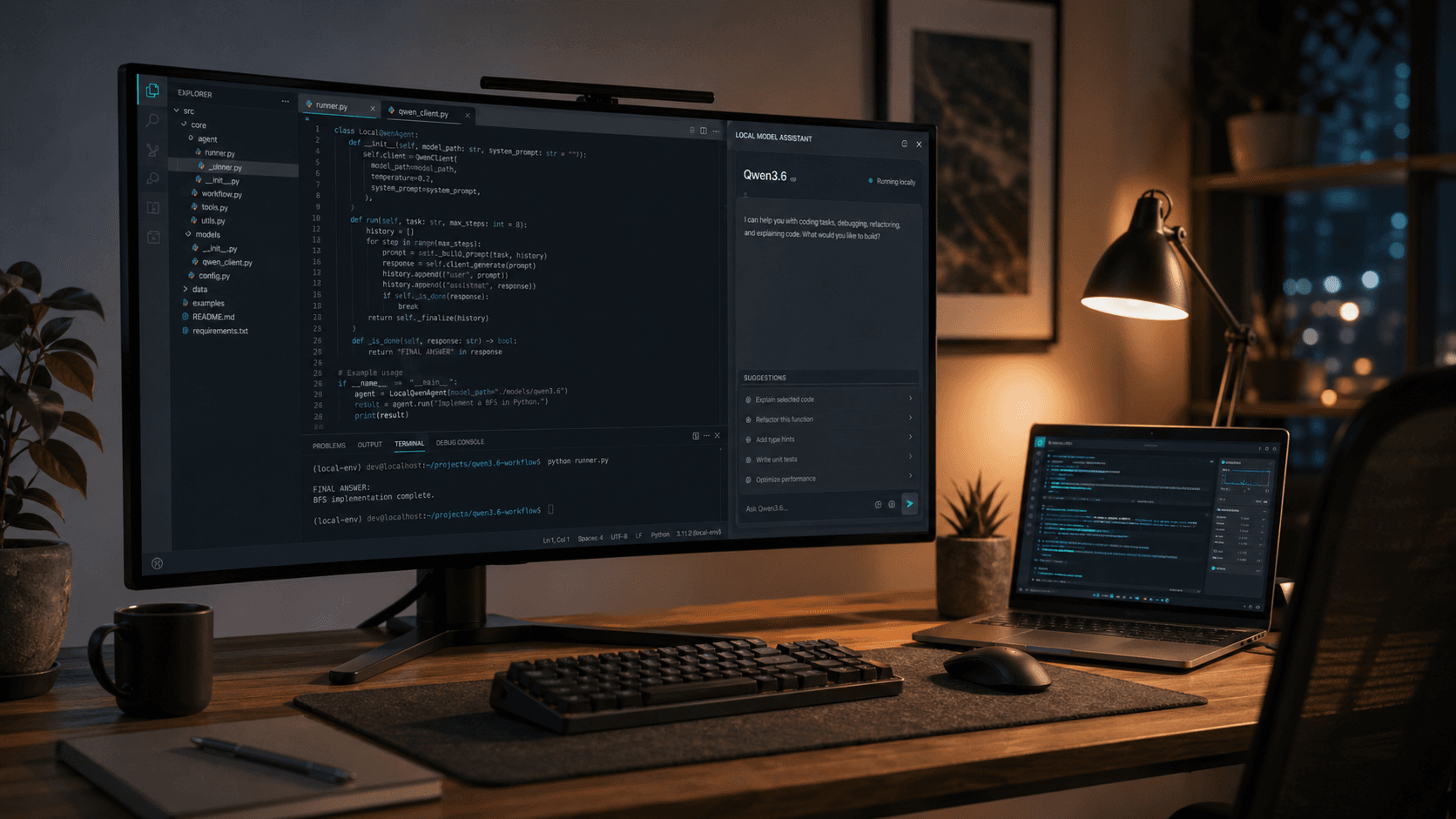
Qwen3.6-27B stands out because it is not only a benchmark update. It is packaged like a model that teams can actually integrate into day-to-day coding and local inference stacks.
As of April 2026, it is available on Hugging Face and appears in Ollama's library, which shortens the path from model release to practical testing.
What Actually Changed
The official model card highlights four practical themes:
- stronger agentic coding behavior for repo-level tasks
- thinking-preservation guidance for multi-step workflows
- native 262,144 token context, with recommendation to keep at least 128K when possible
- clear serving paths via SGLang and vLLM
This makes Qwen3.6-27B relevant for developers who need continuity across long prompts, logs, and cross-file context.
How to Run It Quickly
Fast path: Ollama
For a quick local test loop:
ollama run qwen3.6:35b
Serving path: SGLang
python -m sglang.launch_server \ --model-path Qwen/Qwen3.6-27B \ --port 8000 \ --tp-size 8 \ --mem-fraction-static 0.8 \ --context-length 262144 \ --reasoning-parser qwen3
Serving path: vLLM
vllm serve Qwen/Qwen3.6-27B \ --port 8000 \ --tensor-parallel-size 8 \ --max-model-len 262144 \ --reasoning-parser qwen3
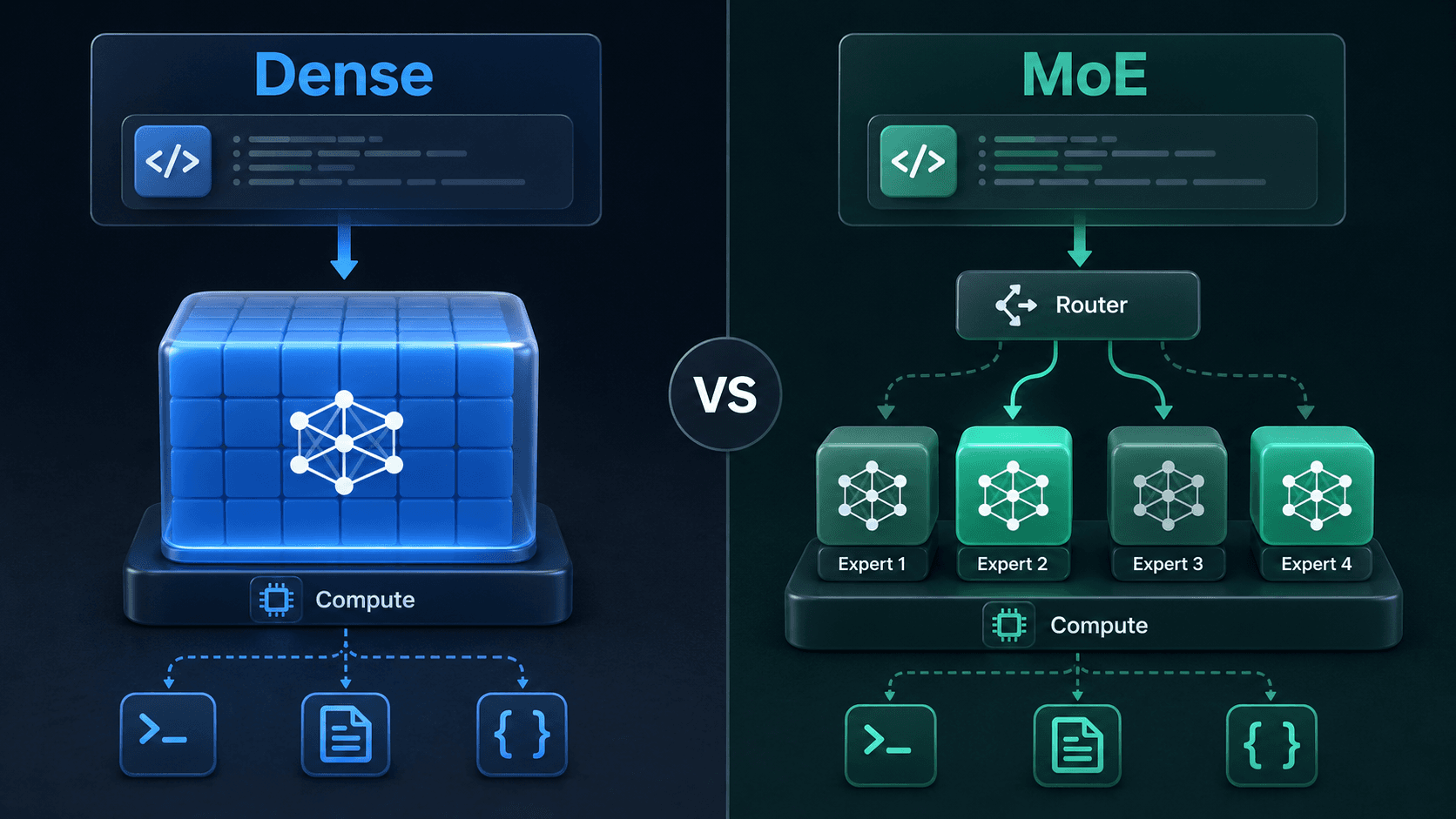
Dense vs MoE: Why It Matters
Qwen3.6 gives teams architecture choice. The 27B model is dense, while 35B-A3B is MoE. That choice affects latency behavior, serving complexity, and hardware pressure.
- dense models are often simpler to reason about operationally
- MoE variants can reduce active-parameter cost in some traffic patterns
The right pick depends on your workload: interactive coding assistant, internal API service, or batch repository analysis.
Practical Evaluation Checklist
- test a real bugfix or feature flow across multiple files
- validate long-context quality against your baseline models
- measure quality and latency across repeated iterative turns
- decide if it fits as primary model, fallback, or privacy-local option
Bottom line: Qwen3.6-27B is worth immediate hands-on testing if your team cares about open local coding workflows.
Sources
- Hugging Face: Qwen/Qwen3.6-27B model card
- Ollama: qwen3.6 model library page